Logistic Regression
- 로지스틱 회귀를 활용해서 분류 문제에 접근할 수 있다.
데이터를 다양한 종류로 나누는 문제를 생각해보자. 가령 이미지가 픽셀의 강도로 주어졌을 때 해당 이미지가 개인지 고양이인지 판별하는 문제를 예로 들 수 있다. 이런 문제에 접근하는 가장 단순한 방법 중 하나가 로지스틱 회귀logistic regression이다.
보통 기계 학습에서 회귀regression라 하면 실수값을 구하는 것을 의미하지만 logistic regression은 데이터를 미리 정해진 개수의 클래스 중 하나로 분류하는 기법이다.
Linear Regression to Logistic Regression
키 정보만을 바탕으로 성별을 추정하는 문제를 고민해보자.
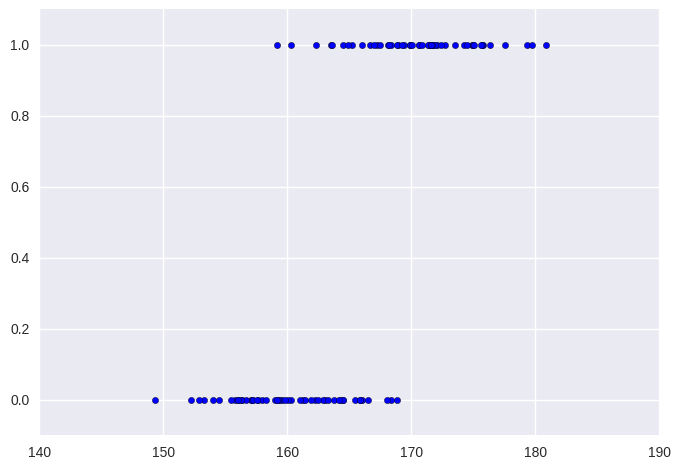
대체로 남성이 여성보다 크기 때문에 키를 바탕으로 사람의 성별을 추정한다면 작으면 높은 확률로 여성이라고 예측하다가 어느 시점에 확률이 높아지고 결국 키가 크다면 남성이라고 예측하는 아주 단순한 접근 방법을 상상해볼 수 있다. 그러므로 먼저 선형 회귀를 통해 데이터와 가장 잘 맞는 직선을 찾는 문제를 풀어보고 이를 활용해볼 수 있을 것이다.
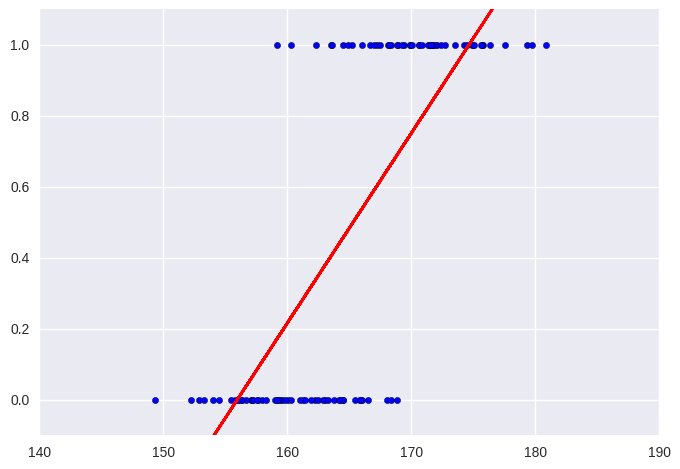
이 결과도 나쁘지는 않다. 가령 0.5가 넘으면 남성 아니라면 여성으로 분류할 수 있을 것이다. 다만 이런 접근 방법은 데이터가 특별히 이런 식으로 잘 맞아 떨어지지 않으면 제대로 동작하지 않는다. 가령 $X$ 축에서 왼편으로 혹은 오른편으로 많이 떨어진 곳에 데이터가 하나 더 생긴다고 생각해보자. 그렇다고 해서 데이터를 분류하는 방식이 크게 영향을 받으면 안 될 것 같다.
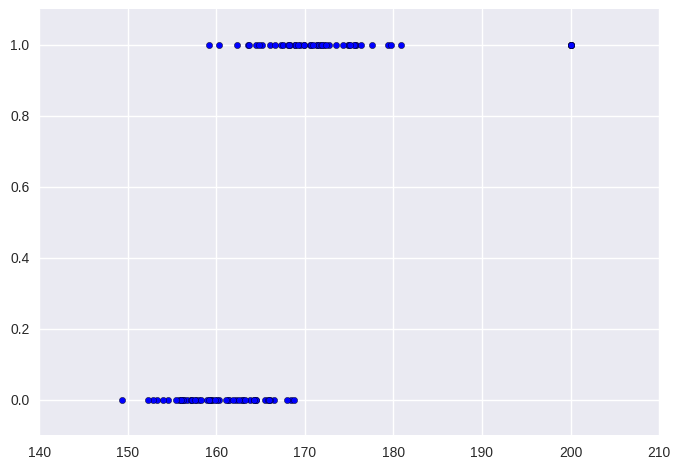
하지만 위와 같이 선형 회귀를 통해 모델을 만든다면 이런 데이터에 의해 결과가 크게 달라지게 된다.
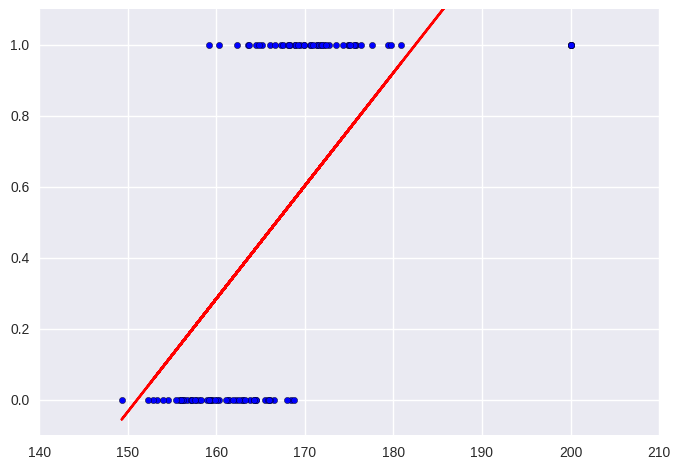
위와 같은 문제가 생기지 않는 방법을 생각해보자. 무작정 직선으로 맞추는 것보다는 부드러운 함수를 사용해서 남성인지 여성인지 여부를 확률값으로 내뱉을 수 있으면 좋을 것이다. 위의 데이터에서는 왼쪽 끝의 값이 입력으로 들어가면 남성이 확률이 거의 0에 가깝게 나오고 오른쪽 끝의 값이 입력으로 들어가면 남성이 확률이 거의 1이 가깝게 나오는 것을 생각해볼 수 있다.
이를 만족하는 함수로 로지스틱logistic 함수가 있다. 이 함수가 S 꼴을 띄기 때문에 흔히 시그모이드sigmoid 함수라고 부른다. 이는 아래와 같다.
$$\sigma(t) = \frac{1}{1 + e^{-t}}$$
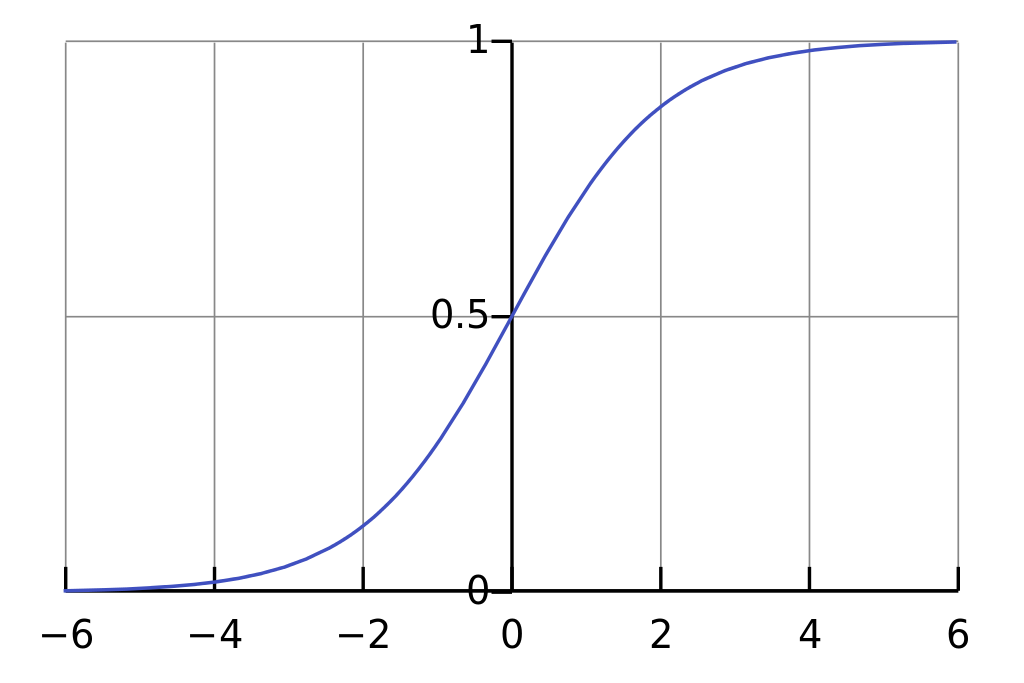
위의 예제에서 선형 회귀를 통해 찾은 직선 $ax + b$는 $x$의 값이 증가하면 함께 증가하는 성질을 갖는다. 이를 위의 로지스틱 함수와 합성하면 로지스틱 회귀를 얻는다.
Point Estimation of Logistic Regression
정식으로 로지스틱 회귀를 표현해보면 아래와 같다.
$$p(y | x, \theta) = Ber(\sigma (w^T x))$$
즉, 선형 회귀와 같은 방식으로 데이터에 대해 가중치를 선형 결합한 뒤 이를 로지스틱 함수를 통과시켜 0과 1사이의 값으로 바꿔서 이를 베르누이Bernoulli 확률 분포의 패러미터로 사용한다. $\sigma(w^T x) = \mu$라 놓고 위의 식을 약간의 트릭을 사용하여 변환하면 아래의 식을 얻는다.
$$p(y | x, w) = \mu^{\mathbb{I}(y = 1)} \cdot (1 - \mu)^{\mathbb{I}(y = 0)}$$
여기에서 양변에 로그를 취하면 아래와 같은 꼴이 된다.
$$\log p(y | x, w) = \mathbb{I}(y = 1) \cdot \log \mu + \mathbb{I}(y = 0) \log (1 - \mu)$$
이는 정보이론information theory에서 다루는 cross entropy와 같은 꼴이다. 그렇기 때문에 이런 loss 함수를 사용하는 때에 cross entropy loss를 사용한다고 표현하기도 한다.
Point estimation을 위해서는 NLL을 각 가중치 $w$로 편미분한 gradient가 필요하다. 우선 로지스틱 함수를 미분하면 아래와 같은 결과를 얻는다.
\begin{align} \frac{\partial \sigma}{\partial t} & = \frac{\partial}{\partial t} \frac{1}{1 + e^{-t}} \\ &= \frac{1}{1 + e^{-t}} \cdot \frac{e^{-t}}{1 + e^{-t}} \\ &= \frac{1}{1 + e^{-t}} (1 - \frac{1}{1 + e^{-t}}) \\ & = \sigma(t) (1 - \sigma(t)) \end{align}
이를 활용해서 likelihood를 미분해보면,
\begin{align} \frac{\partial \log p(y | x, w)}{\partial w_i} & = \mathbb{I}(y = 1) \cdot \frac{1}{\mu} \cdot \frac{\partial \mu}{\partial w_i} + \mathbb{I}(y = 0) \frac{1}{1 - \mu} \frac{\partial (1 - \mu)}{\partial w_i} \\ & = \mathbb{I}(y = 1) (1 - \mu) \cdot x_i + \mathbb{I}(y = 0) (0 - \mu) \cdot x_i \\ & = (y - \mu) \cdot x_i \end{align}
그러므로 NLL에 대한 미분은 $(\mu - y) \cdot x_i$가 된다. 이를 활용해서 SGD로 로지스틱 회귀를 해보자.
def sigmoid(x):
return 1 / (1 + np.e ** (-x))
def grad(x, y, a, b):
return (sigmoid(a*x + b) - y) * x, (sigmoid(a*x + b) - y)
a_hat = 0.1
b_hat = 0.1
stepsize = 0.01
data_mu = np.mean(data)
data_std = np.std(data)
transformed_data = (data - data_mu) / data_std
train_data = list(zip(transformed_data, target))
for i in range(1000):
np.random.shuffle(train_data)
for d, t in train_data:
a_delta, b_delta = grad(d, t, a_hat, b_hat)
a_hat += -stepsize * a_delta
b_hat += -stepsize * b_delta
print(a_hat, b_hat)
plt.clf()
plt.scatter(males, np.ones_like(males))
plt.scatter(females, np.zeros_like(females))
plt.xlim(140, 190)
plt.ylim(-.1, 1.1)
grid = (np.arange(140, 190, 0.5) - data_mu) / data_std
plt.plot(np.arange(140, 190, 0.5), np.array([sigmoid(a_hat*x + b_hat) for x in grid]), 'b', label='Fitted line')
plt.show()
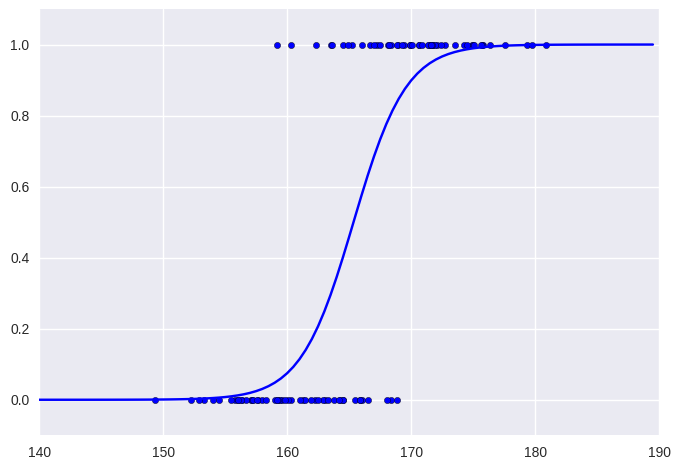
데이터를 평균을 빼고 표준편차로 나누었는데 이를 standardization이라 한다. 이를 통해 얻는 효과는 다양한데 여기에서는 여러 feature가 있을 때 각각을 동등한 정도로 바라보며 SGD를 통한 학습이 잘 수렴할 수 있도록 도와준다. 또한 위에서 매번 데이터를 섞어주는 것은 우리가 데이터 하나만 보고 gradient를 취하기 때문에 특별한 편향이 없게 하기 위함이다.
Multiple Classes
이진 분류가 아니라 더 많은 클래스로 분류해야 하는 경우를 살펴보자. 이때 활용하는 함수는 softmax라 이를 활용하면 likelihood는 아래의 형태가 된다.
$$p(y = c | x, W) = \frac{e^{W_c^T x}}{\sum_{c' \in \mathscr{C}} e^{W_{c'}^T x}}$$
여기에서 $W$는 행렬로 $W_c$는 벡터이고 $W_{ci}$는 $i$번 째 피쳐가 곱해져서 클래스 $c$의 출력으로 나오는 가중치를 나타내게 된다. 잘 살펴보면 위에서 활용한 logistic 함수는 그저 클래스가 두 개인 softmax 함수의 일반화일 뿐이다. 이를 multinomial logistic regression이라 한다. Softmax라는 이름은 $e$의 지수부를 온도 $T$로 나눈다고 할 때 $T$가 커지면 거의 균등분포의 꼴을 띄며 $T$가 작아지면 max 함수와 비슷해지기 때문에 붙은 이름이다. 그저 여기에서는 온도가 1로 고정되었을 뿐이다.
Log likelihood 식은 아래와 같다.
\begin{align} l(W) &= \log \prod_{c \in \mathscr{C}} \mu_{c}^{y_{c}} \\ &= \sum_{c \in \mathscr{C}} y_{c} \log \mu_{c} \\ &= \sum_{c \in \mathscr{C}} \{ y_c (W_c^T x) - y_c \log \sum_{c' \in \mathscr{C}} e^{W_{c'}^T x} \} \\ &= \sum_{c \in \mathscr{C}} \{ y_c (W_c^T x) \} - \sum_{c \in \mathscr{C}} \{ y_c \log \sum_{c' \in \mathscr{C}} e^{W_{c'}^T x} \} \\ &= \sum_{c \in \mathscr{C}} \{ y_c (W_c^T x) \} - \log \sum_{c' \in \mathscr{C}} e^{W_{c'}^T x} \sum_{c \in \mathscr{C}} \{ y_c \} \\ &= \sum_{c \in \mathscr{C}} \{ y_c (W_c^T x) \} - \log \sum_{c' \in \mathscr{C}} e^{W_{c'}^T x} \\ \end{align}
이제 이에 대한 미분을 구해보자.
\begin{align} \frac{\partial l(W)}{\partial W_{ci}} &= y_c x_i - \frac{1}{\sum_{c' \in \mathscr{C}} e^{W_{c'}^T x}} \cdot e^{W_{c}^T x} \cdot x_i \\ &= y_c x_i - \mu_c x_i \end{align}
그러므로 NLL에 대한 편미분은 이에 음수를 취한 $(\mu_c - y_c)\cdot x_i$이다.
Multinomial Logistic Regression Example
예제를 통해 조금 더 자세히 살펴보자. 세 개의 클래스가 있고 두 개의 피쳐가 있는 경우 gradient 업데이트 규칙은 아래와 같다.
\begin{bmatrix} (\mu_{1} - y_{1}) x_{1}\\ (\mu_{1} - y_{1}) x_{2}\\ (\mu_{2} - y_{2}) x_{1}\\ (\mu_{2} - y_{2}) x_{2}\\ \end{bmatrix}
세 번째 클래스의 gradient 업데이트가 없는 이유는 세 번째 클래스의 입력으로 들어가는 가중치들을 모두 0으로 고정했기 때문이다. 그렇지 않으면 완전히 같은 모델이지만 가중치가 다른 경우가 생길 수 있다.
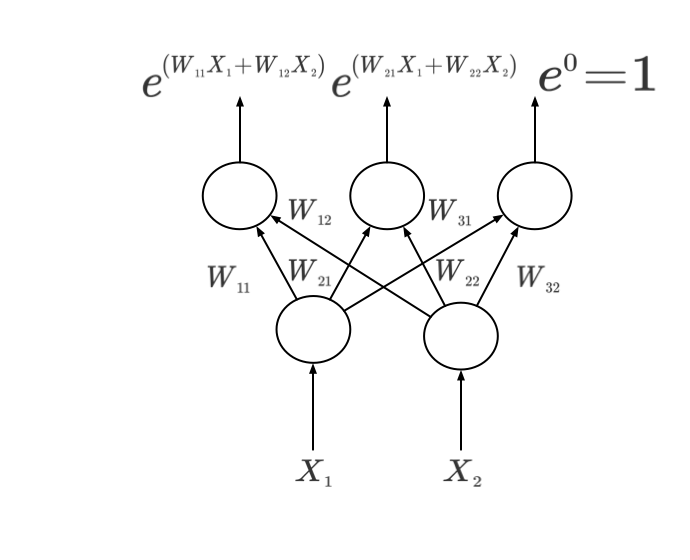
업데이트 식을 음미해보면 $W_{11}$이 $(\mu_{1} - y_{1}) X_{1}$을 통해 갱신된다. 즉, 결과와 예측의 차이에 특정 피쳐가 영향을 끼친 만큼이 보정되어 업데이트 된다. 이런 꼴의 업데이트 식은 다양한 곳에서 나타난다.
Reference
위의 로지스틱 함수의 그림은 위키피디아의 Logistic function 항목에서 가져왔다.
분류를 위해 사용하는 시그모이드 함수는 반드시 로지스틱 함수일 필요는 없다. 가령 정규분포의 CDF를 활용한 probit regression 등도 있다. 하지만 로지스틱 함수를 굳이 사용하는 나름의 이유가 있는데 이는 정보이론의 관점에서 해석할 수 있다.
선형 회귀와 다르게 로지스틱 회귀는 적당한 conjugate prior가 존재하지 않는다. 그렇기 때문에 정확한 계산은 쉽지 않으며 위와 같이 point estimation을 하거나 다른 종류의 근사 추정 기법을 사용해야 한다.