Linear Regression
- 선형 회귀 소개.
- SGD 소개.
- Regularization 소개.
가장 단순한 모델 중 하나인 선형 회귀linear regression를 알아보자. 선형 회귀는 데이터를 가장 잘 설명하는 초평면을 찾는 모델로 생각할 수 있다.
선형 회귀 모델은 $i$-번째 점 $x^{(i)} = \{x_1^{(i)}, \ldots, x_k^{(i)}\}$에 대응되는 값 $y^{(i)}$가 데이터의 피쳐 $x_j^{(i)}$들의 선형 결합으로 만들어진다고 가정한다. 우리가 관측하는 데이터에는 늘 약간의 오차가 있게 마련이고 이 오차가 표준편차 $\sigma$를 갖는다고 가정하면 아래와 같은 식으로 쓸 수 있다.
$$y = \sum_{i=1}^{k} w_i x_i + b + \epsilon \text{, where } \epsilon \sim N(0, \sigma^2)$$
이는 생각해보면 $w_i$에 의해서 평면의 방향이 결정되고 $b$에 의해 해당 평면이 원점으로부터 얼마나 떨어져 있는지 결정되는 모델인 셈이다.
The Big Picture of Machine Learning에서 논하였듯, 우리가 관심 있는 것은 모델 패러미터의 posterior 분포를 구하는 것이다. 베이즈 정리를 다시 써보면 아래와 같다.
$$p(\theta | D) = \frac{p(D | \theta) p(\theta)}{p(D)}$$
여기에서는 $\theta = (w_1, w_2, \ldots, w_k, b)$이다.
이를 구하는 가장 쉬운 접근 중 하나인 point estimation 기법을 살펴보자.
Maximum Likelihood Estimation
Posterior 분포를 점으로 근사하는 방법을 살펴보자. 즉, posterior의 값을 가장 크게 만드는 한 점에 대응되는 $\theta$를 찾는 것이 목표이다.
$$\mathrm{argmax}_{\theta} p(\theta | D) = \mathrm{argmax}_{\theta} \log p(\theta | D) = \mathrm{argmax}_{\theta} \log (p(D | \theta) p(\theta))$$
Log는 단조증가함수이므로 값의 비교에 영향을 주지 않으며, 비슷하게 분모에 있는 $p(D)$는 $\theta$의 영향을 받지 않으므로 무시할 수 있다.
만약 $p(\theta)$가 모든 $\theta$에 대해 같다면, 위에서 무시한 항과 비슷하게 이 또한 $\theta$의 값에 무관하므로 제거할 수 있게 된다. 그렇다면 아래와 같이 식이 변형된다.
$$\mathrm{argmax}_{\theta} p(\theta | D) = \mathrm{argmax}_{\theta} \log p(D | \theta) = \mathrm{argmin}_{\theta} - \log p(D | \theta)$$
$p(D | \theta)$는 likelihood이며 그래서 위의 변환된 식을 negative log likelihood (NLL) 라 한다. 그리고 위의 식을 만족하는 $\theta$를 maximum likelihood estimate (MLE) 라고 부른다. 앞서 말했다시피 $p(\theta | D)$를 MLE로 근사하게 된다.
총 $n$개의 데이터가 있다면, posterior 분포는 아래와 같다.
$$p(D | \theta) = \prod_{i=1}^{n} p(y^{(i)} | x^{(i)}, \theta)$$ $$\log p(D | \theta) = \sum_{i=1}^{n} \log p(y^{(i)} | x^{(i)}, \theta)$$
각각의 데이터가 독립적으로 생성되었다는 가정을 하면 전체의 likelihood는 각각의 likelihood의 곱이므로 위와 같은 방식의 변환이 가능하다.
One Dimensional Example
조금 더 구체적으로 알아보기 위해 가장 이해하기 쉬운 1차원 데이터의 경우를 살펴보자. 1차원 데이터를 생각해보면 레이블까지 포함해서 2차원 평면을 이루고 이 공간을 가로지르는 초평면은 단순한 직선이 된다.
import numpy as np
import matplotlib.pylab as plt
a = 1.5
b = 10.0
x = np.arange(0, 30, step=0.5)
y = a * x + b + np.random.normal(0, 2, size=len(x))
# show scatter plot with ground truth line
plt.scatter(x, y)
plt.plot(x, a*x + b, label='Ground Truth')
plt.legend()
plt.show()

오차가 정규분포Gaussian distribution로부터 나온다고 가정했으니 정규분포의 확률밀도함수probability density function를 살펴보자. 평균이 $\mu$이고 표준편차가 $\sigma$인 정규분포의 확률밀도함수는 아래와 같다.
$$f(x) = \frac{1}{\sqrt{2 \sigma^2 \pi}} e^{- \frac{(x - \mu)^2}{2 \sigma^2}}$$
이 경우 $\theta = (a, b)$이며 $a$는 직선의 기울기에, $b$는 $y$ 절편에 대응된다. 그러므로 위의 식은 아래와 같이 구체화할 수 있다.
$$p(y | x, \theta) = \frac{1}{\sqrt{2 \sigma^2 \pi}} e^{- \frac{(y - (ax + b))^2}{2 \sigma^2}}$$
양변에 로그를 씌우면 아래와 같이 변한다.
$$\log p(y | x, \theta) = - \frac{(y - (ax + b))^2}{2 \sigma^2} + C$$
$- \log p(y | x, \theta)$를 최소화하는 것이 목표인데 다른 항들은 $a$와 $b$의 변화에 영향을 받지 않으므로 결과적으로 $(y - (ax + b))^2$의 최소화만 신경 쓰면 된다. 위의 최소화 문제를 푸는 것으로 선형회귀를 접하는 경우가 많다. 이를 보통 최소자승법least squares라 부른다.
함수의 최소값을 찾는 것은 자연스레 gradient를 찾는 것으로 생각이 옮겨간다. Gradient란 각 변수로 함수를 편미분한 것의 벡터를 의미한다. Gradient는 특정 점에서 함수가 가장 빠르게 증가하는 방향을 가리키므로 그 반대 방향으로 움직이면 가장 빠르게 함수가 감소하는 방향이 된다. NLL을 $a$와 $b$로 각각 편미분하면 아래와 같은 식을 얻는다.
$$\frac{\partial NLL}{\partial a} = -2(y - (ax + b))x$$ $$\frac{\partial NLL}{\partial b} = -2(y - (ax + b))$$
패러미터 공간의 임의의 점에서 출발하여 gradient의 반대 방향으로 조금씩 이동하는데, 이때 NLL을 하나의 점에 대해서만 계산하고 매번 계산할 때 다음 데이터를 사용한다. 이런 접근 방법을 stochastic gradient descent (SGD)라 한다.
def grad(x, y, a_hat, b_hat):
return (-(y - (a_hat * x + b_hat)) * x, -(y - (a_hat * x + b_hat)))
# perform gradient descent
a_hat = 0.1; b_hat = 0.1; stepsize = 0.0001
theta_list = [(a_hat, b_hat)]
for epoch in range(10000):
for feature, label in zip(x, y):
a_grad, b_grad = grad(feature, label, a_hat, b_hat)
a_hat -= stepsize * a_grad
b_hat -= stepsize * b_grad
theta_list.append((a_hat, b_hat))
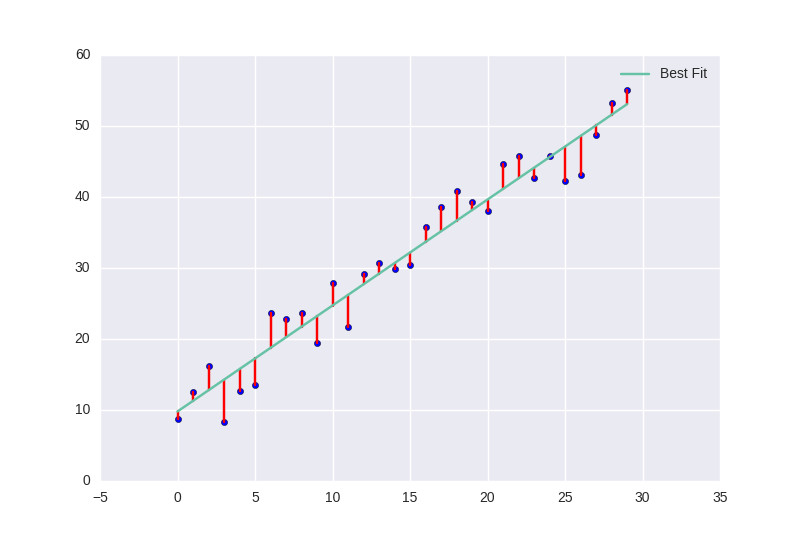
print(a_hat, b_hat) # 1.4914122716536715 9.8244846147747129
# show plot with best fit
plt.scatter(x, y)
plt.plot(x, a*x + b, label='Ground Truth')
plt.plot(x, a_hat*x + b_hat, label='Best Fit')
plt.legend()
plt.show()
SGD의 결과로 $a = 1.4914122716536715$와 $b = 9.8244846147747129$를 추정치로 찾았다. 차트를 살펴보면 이렇게 찾은 직선과 실제 직선이 거의 일치함을 확인할 수 있다.
SGD는 임의의 점에서 시작하는데, 이 경우 (0.1, 0.1)에서 출발하여 gradient의 반대 방향으로 조금씩 이동하며 모델 공간을 탐색한다.
Maximum A Posteriori
이번엔 모든 패러미터가 동등하게 그럴싸하다는 가정을 없애보자.
$$\mathrm{argmax}_{\theta} p(\theta | D) = \mathrm{argmax}_{\theta} \log p(D | \theta) + \log p(\theta) = \mathrm{argmin}_{\theta} - \log p(D | \theta) - \log p(\theta)$$
만약 $p(\theta)$도 정규분포를 따른다면 어떨까?
$$\theta \sim N(0, \tau^2)$$
$\epsilon$항과 같은 논리로 $p(\theta)$는 최적화 해야 하는 목적함수objective function에서 $\sum_i \theta_i^2$로 변하게 된다. 그러므로 최종적으로 최적화해야 하는 목적함수는 다음과 같다.
$$(y - (ax + b))^2 + \lambda (a^2 + b^2)$$
새롭게 추가된 항을 regularization이라고 부른다. 이는 패러미터가 터무니없는 값으로 폭발하는 것을 막아주며 모델이 관측하지 않은 미래의 데이터에 대해 더 잘 generalize 할 수 있도록 도와준다. 여기에서 $\lambda$는 regularization이 전체의 목적함수에 끼치는 영향의 정도를 조절한다. 이처럼 패러미터의 제곱을 regularization 항으로 선형회귀에 포함시키는 것을 ridge regression 이라 한다. 참고로 이처럼 베이지안 관점에서 prior를 함께 고려하는 것만으로 자연스레 regularization이 등장함을 눈여겨 볼만하다.
보통 위와 같이 regularization을 포함할 때 $y$ 절편은 빼주도록 한다. 실제 데이터가 원점으로부터 멀리 떨어져 있는데 굳이 그 거리를 제한하는 것이 합리적이지 않을 수 있기 때문이다.
그 경우 gradient는 다음과 같이 변한다.
\begin{align} \frac{\partial NLL}{\partial a} & = -2(y - (ax + b))x + 2\lambda a \\ \frac{\partial NLL}{\partial b} & = -2(y - (ax + b)) \end{align}
위에서 주어진 새로운 목적함수와 gradient를 사용하여 SGD를 수행하여 얻게 되는 추정치를 Maximum A Posteriori (MAP)이라 부른다. 이런 단순한 경우에는 regularization의 도입이 불필요해 보일 수 있으나 더 나은 generalization을 위해 거의 항상 모델의 복잡도를 조절하는 regularization을 사용할 필요가 있다.
Matrix Form
선형 회귀는 말 그대로 선형 연산만 사용하기 때문에 행렬을 조작하는 것으로 추정 문제를 풀 수 있다. 편의상 절편에 대응되는 변수를 제외하고 생각해보면, 데이터 $X$ 가 $n \times k$ 행렬이고, $w$ 는 $k$ 차원 벡터이다. 이제 원래 고려하던 오차의 제곱합을 목적함수로 쓰면 아래와 같다.
$$L = (y - \hat{y})^T (y - \hat{y}) = (y - Xw)^T (y - Xw)$$
위의 식을 최소화 하는 것이 목적인데, 이는 이차 형식quadratic form을 띄고 있으므로 gradient가 0인 지점에서 최소값을 가질 것이다. 행렬의 differential을 계산해보면 아래와 같다.
$$\begin{array}{ccl} dL &=& (-X dw)^T (y - Xw) + (y - Xw)^T (-X dw)\\ &=& tr((- Xdw)^T (y - Xw)) + tr((y - Xw)^T(-Xdw))\\ &=& tr((y - Xw)^T (-Xdw)) + tr((y - Xw)^T (-Xdw))\\ &=& 2 tr((y - Xw)^T (-Xdw)) \end{array}$$
Differential이 0이라는 점을 사용하면,
$$\begin{array}{l} (y - Xw)^TX = 0 \\ y^TX - w^TX^TX = 0\\ y^TX = w^TX^TX\\ X^Ty = (X^TX)^Tw\\ w = (X^TX)^{-1}X^Ty\\ \end{array}$$
마지막 부분에서 $(X^TX)$ 의 역행렬을 구할 수 있으려면 행렬 $X$ 가 ($n > k$ 라는 조건하에서) rank $k$ 이어야 한다.
위의 과정에서 구한 $(X^TX)^{-1}X^T$ 가 Moore-Penrose pseudo-inverse 이다. 이는 역행렬이 존재하지 않는 행렬을 마치 역행렬이 있는 것처럼 취급할 수 있게 해준다. 그 의미를 음미해보면 다음과 같다. 행렬을 선형 변환이라는 관점에서 생각해볼 때, $n \times m$ 행렬은 $m$ 차원 데이터를 $n$ 차원으로 사상하는 것인데, pseudo-inverse 는 거꾸로 $n$ 차원 데이터를 $m$ 차원으로 사상한다. 이 사상은 $n$ 차원 데이터를 $m$ 차원으로 보냈다가 다시 원래의 변환을 사용하여 $n$ 차원으로 돌아왔을 때, 원래의 $n$ 차원 데이터와의 차이(오차의 제곱합)가 최소화 되는 변환이다.
Reference
1809년 Gauss는 Theoria motus corporum coelestium in sectionibus conicis solem ambientium에서 least squares, MLE, 정규분포의 개념을 소개하였다. 여기에서 소개된 방법을 사용해서 세레스Ceres의 궤도를 추정하는 문제를 풀 수 있었다. 1810년 Laplace가 중심극한정리central limit theorem를 증명한 뒤 이를 활용해 least squares에서 정규분포 가정의 정당성을 논하게 된다.
위에서 소개된 SGD 기반의 MLE 추정이 아니라 정확한 MLE를 계산하는 것도 가능하다. 이는 선형 회귀에서 모든 것이 선형성을 바탕으로 이루어지기 때문에 행렬의 결합으로 계산될 수 있음을 활용하면 가능하다. 이렇게 찾은 MLE에 대해 신뢰 구간 등의 추정을 함께 하는 것이 전통적인 빈도주의frequentist의 접근 방법이다. 한편, 정규분포 가정 덕분에 적절한 conjugate prior가 존재하고 그러므로 베이지안 관점에서 posterior 분포에 대한 모든 것을 풀어낼 수도 있다.